
The paper addresses the limitations of large language models (LMs) in generating accurate and factual output. While these models are proficient at understanding and generating text, they often produce incorrect or “hallucinated” information. One way to rectify this is by augmenting LMs with external data sources, but most existing approaches have limitations. Specifically, they usually retrieve information just once based on the initial input, which is insufficient for generating longer, more complex texts.
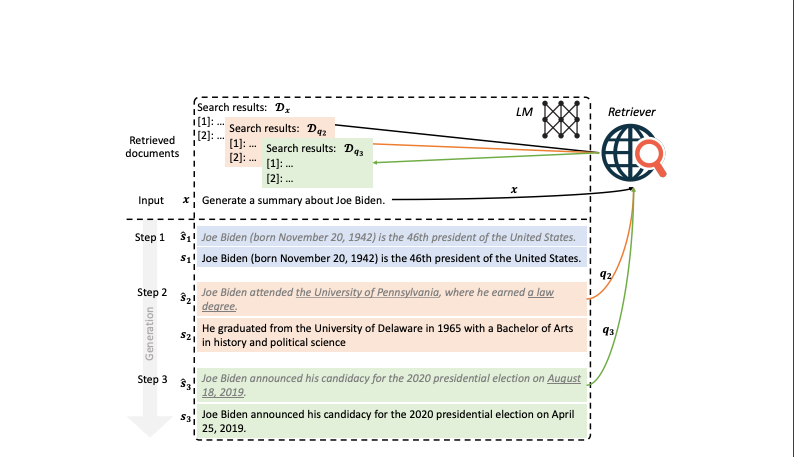
To tackle this issue, the authors introduce a new approach called Forward-Looking Active REtrieval augmented generation (FLARE). Unlike conventional methods, FLARE dynamically decides when and what information to retrieve while generating text. It does so by predicting the content of upcoming sentences and using these predictions as queries to pull in relevant external information. This is particularly useful for regenerating sentences that contain low-confidence tokens.
The FLARE method was extensively tested on four long-form, knowledge-intensive tasks and datasets. The results showed that FLARE either outperformed or was competitive with existing methods, thereby proving its effectiveness.
Key Concepts from the Paper:
- Existing retrieval augmented LMs only retrieve once based on the input. This is limiting for long-form generation where retrieving multiple times is needed.
- FLARE retrieves when the LM generates low-confidence tokens, indicating lack of knowledge. This avoids unnecessary retrieval.
- To determine what to retrieve, FLARE generates a temporary next sentence, uses it to query relevant documents if it has unsure tokens, and regenerates the sentence with the retrieved docs.
- Using the upcoming content as queries enables retrieving information relevant for future generation.
- FLARE outperforms baselines on multi-hop QA, commonsense reasoning, long-form QA, and summarization.
Below is a very nice video which explains the concept of FLARE.
In summary, FLARE is a simple but effective method for actively integrating retrieval with language model generation to improve performance on long-form text generation tasks. The key ideas are retrieving only when needed during generation, and using predicted upcoming content to retrieve information relevant for future generation.


